Indexes
When using ElectroDB, indexes are referenced by their AccessPatternName. This allows you to maintain generic index names on your DynamoDB table, but reference domain specific names while using your ElectroDB Entity. These will be referenced as “Access Patterns”.
All DynamoDB table start with at least a PartitionKey with an optional SortKey, this can be referred to as the “Table Index”. The indexes object requires at least the definition of this Table Index Partition Key and (if applicable) Sort Key.
In your model, the Table Index this is expressed as an Access Pattern without an index property. For Secondary Indexes (both GSIs and LSIs), use the index property to define the name of the index as defined on your DynamoDB table.
The ‘index’ property is simply a mapping of your AccessPatternName to your DynamoDB index name. They allow you to easily create composite keys, and dictate the order of in which your composite attributes are applied. ElectroDB does not create or alter DynamoDB tables, so your indexes will need to be created prior to use.
Within these AccessPatterns, you define the PartitionKey and (optionally) SortKeys that are present on your DynamoDB table and map the key’s name on the table with the field property.
Index Definition
indexes: {
[AccessPatternName]: {
index?: string;
collection?: string | string[];
type?: 'isolated' | 'clustered';
pk: {
field: string;
composite: AttributeName[];
template?: string;
cast?: 'string' | 'number';
casing?: 'upper' | 'lower' | 'none';
},
sk?: {
field: string;
composite: AttributesName[];
template?: string;
cast?: 'string' | 'number';
casing?: 'upper' | 'lower' | 'none';
},
}
}Index Options
| Property | Type | Required | Description |
|---|---|---|---|
index | string | no | Required when the Index defined is a Global/Local Secondary Index; but is omitted for the table’s primary index. |
collection | string, string[] | no | Used when models are joined to a Service. When two entities share a collection on the same index, they can be queried with one request to DynamoDB. The name of the collection should represent what the query would return as a pseudo Entity; See the page on Collections for more information on this functionality. |
type | isolated, clustered | no | Allows you to optimize your index for either entity isolation (high volume of records per partition) or entity relationships (high relationship density per partition). When omitted, ElectroDB defaults to isolation. |
condition | (attr: T) => boolean | no | A function that accepts all attributes provided every mutation method and returns a boolean value. When provided, ElectroDB will use this function to determine if an index should be be written given a provided set of attributes. This is useful for implementing “sparse” indexes, See the second on Sparse Indexes below for more information on this functionality |
pk | object | yes | Configuration for the pk of that index or table |
pk.composite | string[] | yes | An array that represents the order in which attributes are concatenated to composite attributes the key (see Composite Attributes below for more on this functionality). |
pk.template | string | no | A string that represents the template in which attributes composed to form a key (see Composite Attribute Templates below for more on this functionality). |
pk.field | string | yes | The name of the index Partition Key field as it exists in DynamoDB, if named differently in the schema attributes. |
pk.casing | default, upper, lower, none | no | Choose a case for ElectroDB to convert your keys to, to avoid casing pitfalls when querying data. Default: lower. |
pk.cast | string, number | no | The cast option allows you to define a different primitive type for your key than your attribute. When number is used, you are only allowed to have one composite attribute, string values are validated at runtime with parseInt, and booleans are cast to 1 or 0. Default: string. |
sk | object | no | Configuration for the sk of that index or table |
sk.composite | string[] | no | Either an Array that represents the order in which attributes are concatenated to composite attributes the key, or a String for a composite attribute template. (see Composite Attributes below for more on this functionality). |
sk.template | string | no | A string that represents the template in which attributes composed to form a key (see Composite Attribute Templates below for more on this functionality). |
sk.field | string | yes | The name of the index Sort Key field as it exists in DynamoDB, if named differently in the schema attributes. |
sk.casing | default, upper, lower, none, | no | Choose a case for ElectroDB to convert your keys to, to avoid casing pitfalls when querying data. Default: lower. |
sk.cast | string, number | no | The cast option allows you to define a different primitive type for your key than your attribute. When number is used, you are only allowed to have one composite attribute, string values are validated at runtime with parseInt, and booleans are cast to 1 or 0. Default: string. |
Composing Indexes
A Composite Attribute is a segment of a key based on one of the attributes. Composite Attributes are concatenated together from either a Partition Key, or a Sort Key, which define an index.
Only attributes with a type of
"string","number","boolean", orstring[](enum) can be used as composite attributes.
There are two ways to provide composite:
For example, in the following Access Pattern, ”locations” is made up of the composite attributes storeId, mallId, buildingId and unitId which map to defined attributes in the schema:
Input
{
"storeId": "STOREVALUE",
"mallId": "MALLVALUE",
"buildingId": "BUILDINGVALUE",
"unitId": "UNITVALUE"
};Output
{
"pk": "$mallstoredirectory_1#storeId_storevalue",
"sk": "$mallstores#mallid_mallvalue#buildingid_buildingvalue#unitid_unitvalue"
}For PK values, the service and version values from the model are prefixed onto the key.
For SK values, the entity value from the model is prefixed onto the key.
Composite Attribute Arrays
Within a Composite Attribute Array, each element is the name of the corresponding Attribute defined in the Model. The attributes chosen, and the order in which they are specified, will translate to how your composite keys will be built by ElectroDB.
If the Attribute has a
labelproperty, that will be used to prefix the composite attributes, otherwise the full Attribute name will be used.
Example
attributes: {
storeId: {
type: "string",
label: "sid",
},
mallId: {
type: "string",
label: "mid",
},
buildingId: {
type: "string",
label: "bid",
},
unitId: {
type: "string",
label: "uid",
}
},
indexes: {
locations: {
pk: {
field: "pk",
composite: ["storeId"]
},
sk: {
field: "sk",
composite: ["mallId", "buildingId", "unitId"]
}
}
}Input
{
"storeId": "STOREVALUE",
"mallId": "MALLVALUE",
"buildingId": "BUILDINGVALUE",
"unitId": "UNITVALUE"
};Output
{
"pk": "$mallstoredirectory_1#sid_storevalue",
"sk": "$mallstores#mid_mallvalue#bid_buildingvalue#uid_unitvalue"
}Composite Attribute Templates
You may have found examples online that demonstrate how to make keys for Single Table Design. These patterns often look like user#${id} or org#${id}. ElectroDB creates keys similar to these patterns out of the box without the need for using “template”. It is highly recommended to only use “template” when you are attempting to use ElectroDB on an existing table/dataset. If you are starting a new project, you should not need to use “template”, and using it will limit some protections and features granted by ElectroDB.
With a Composite Template, you provide a formatted template for ElectroDB to use when making keys. Composite Attribute Templates allow for potential ElectroDB adoption on already established tables and records.
Attributes are identified by surrounding the attribute with ${...} braces. For example, the syntax ${storeId} will match storeId attribute in the model.
Convention for a composing a key use the # symbol to separate attributes, and for labels to attach with underscore. For example, when composing both the mallId and buildingId would be expressed as mid_${mallId}#bid_${buildingId}.
ElectroDB will not prefix templated keys with the Entity, Project, Version, or Collection. This will give you greater control of your keys but will limit ElectroDB’s ability to prevent leaking entities with some queries.
Example
{
model: {
entity: "MallStoreCustom",
version: "1",
service: "mallstoredirectory"
},
attributes: {
storeId: {
type: "string"
},
mallId: {
type: "string"
},
buildingId: {
type: "string"
},
unitId: {
type: "string"
}
},
indexes: {
locations: {
pk: {
field: "pk",
composite: ["storeId"],
template: "sid_${storeId}"
},
sk: {
field: "sk",
composite: ["mallId", "buildingId", "unitId"],
template: "mid_${mallId}#bid_${buildingId}#uid_${unitId}"
}
}
}
}Input
{
"storeId": "STOREVALUE",
"mallId": "MALLVALUE",
"buildingId": "BUILDINGVALUE",
"unitId": "UNITVALUE"
};Output
{
"pk": "sid_storevalue",
"sk": "mid_mallvalue#bid_buildingvalue#uid_unitvalue"
}Composite Attribute and Index Considerations
As described in the above two sections (Composite Attributes, Indexes), ElectroDB builds your keys using the attribute values defined in your model and provided on your query. Here are a few considerations to take into account when thinking about how to model your indexes:
-
Your table’s primary Partition and Sort Keys cannot be changed after a record has been created. Be mindful of not to use Attributes that have values that can change as composite attributes for your primary table index.
-
When updating/patching an Attribute that is also a composite attribute for secondary index, ElectroDB will perform a runtime check that the operation will leave a key in a partially built state. For example: if a Sort Key is defined as having the Composite Attributes
["prop1", "prop2", "prop3"], than an update to theprop1Attribute will require supplying theprop2andprop3Attributes as well. This prevents a loss of key fidelity because ElectroDB is not able to update a key partially in place with its existing values. -
As described and detailed in Composite Attribute Arrays, you can use the
labelproperty on an Attribute shorten a composite attribute’s prefix on a key. This can allow trim down the length of your keys.
Index Mapping
ElectroDB supports many ways to map your indexes to your unique table. From indexes with only a partition key, to numeric sort keys, to existing tables with unconventional key structures. You can learn more about how your indexes map to your table definition on the Schema page.
Index Types
ElectroDB helps manage your key structure, and works to abstract out the details of how your keys are created/formatted. Depending on your unique data set, you may need ElectroDB to optimize your index for either entity isolation (i.e. high volume of records per partition) or entity relationships (i.e. high relationship density per partition).
This option changes how ElectroDB formats your keys for storage, so it is an important consideration to make early in your modeling phase. As a result, this choice cannot be simply walked back without requiring a migration. The choice between clustered and isolated depends wholly on your unique dataset and access patterns.
You can use Collections with both
isolatedandclusteredindexes. Isolated indexes are limited to only querying across the partition key while Clustered indexes can also leverage the Sort Key.
Isolated Indexes
By default, and when omitted, ElectroDB will create your index as an isolated index. Isolated indexes optimizes your index structure for faster and more efficient retrieval of items within an individual Entity.
Choose isolated if you have strong access pattern requirements to retrieve only records for only your entity on that index. While an isolated index is more limited in its ability to be used in a collection, it can perform better than a clustered index if a collection contains a highly unequal distribution of entities within a collection.
Don’t choose isolated if the primary use-cases for your index is to query across entities — this index type does limit the extent to which indexes can be leveraged to improve query efficiency.
Clustered Indexes
When your index type is defined as clustered, ElectroDB will optimize your index for relationships within a partition. Clustered indexes optimize your index structure for more homogenous partitions, which allows for more efficient queries across multiple entities.
Choose clustered if you have a high degree of grouped or similar data that needs to be frequently accessed together. This index works best in collections when member entities are more evenly distributed within a partition.
Don’t choose clustered if your need to query across entities is secondary to its primary purpose — this index type limits the efficiency of querying your individual entity.
Isolated vs Clustered
The following images illustrate the difference between an isolated and clustered index type. Each blue line represents an “employee” entity record and each yellow line represents a “task” entity record.
In this example, the following records have the same partition key composite attributes.
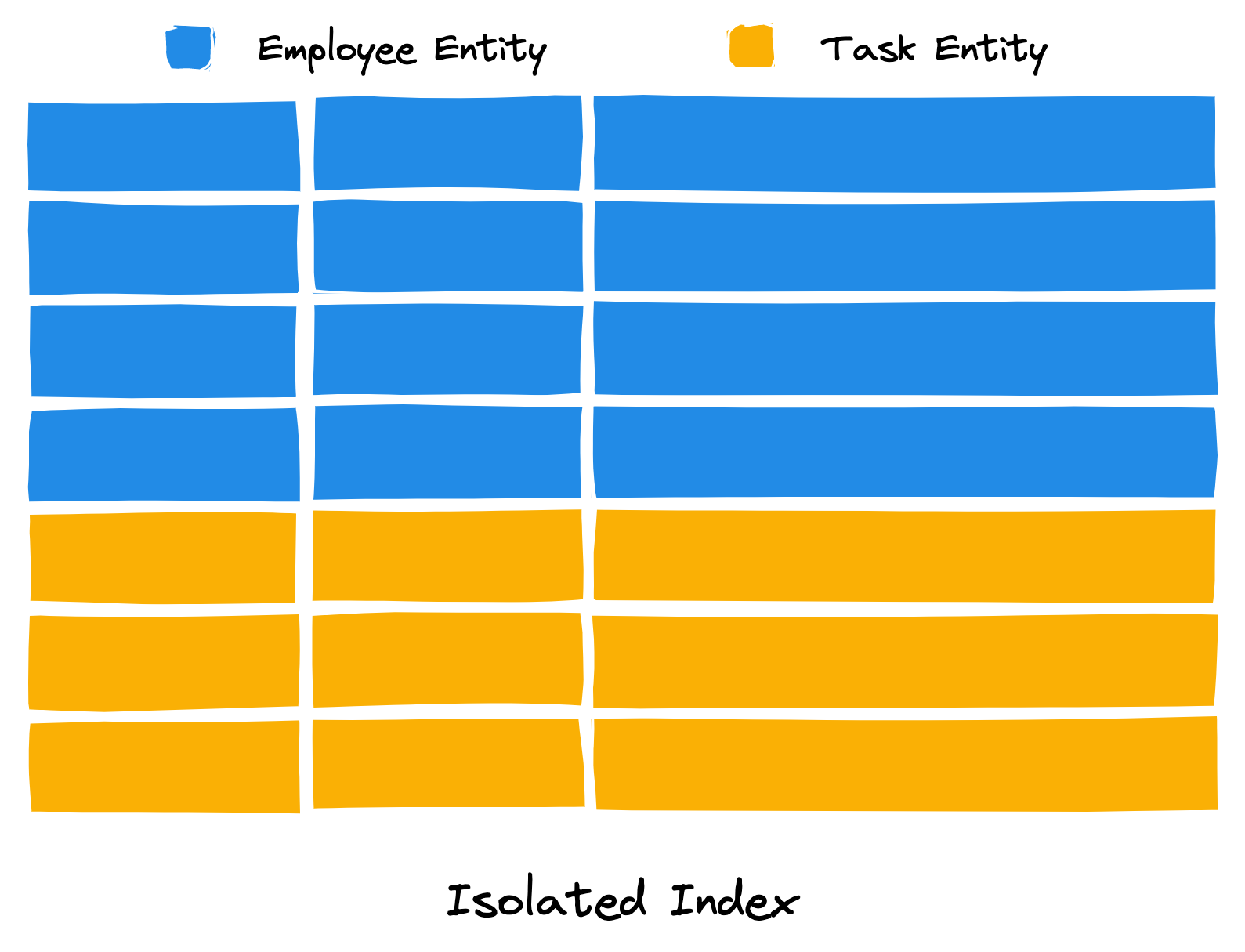
In an isolated index type, entities sharing a partition key do not co-mingle. While this is not ideal for querying across entities, it is ideal for efficently targetting (or “isolating”) a single entity type.
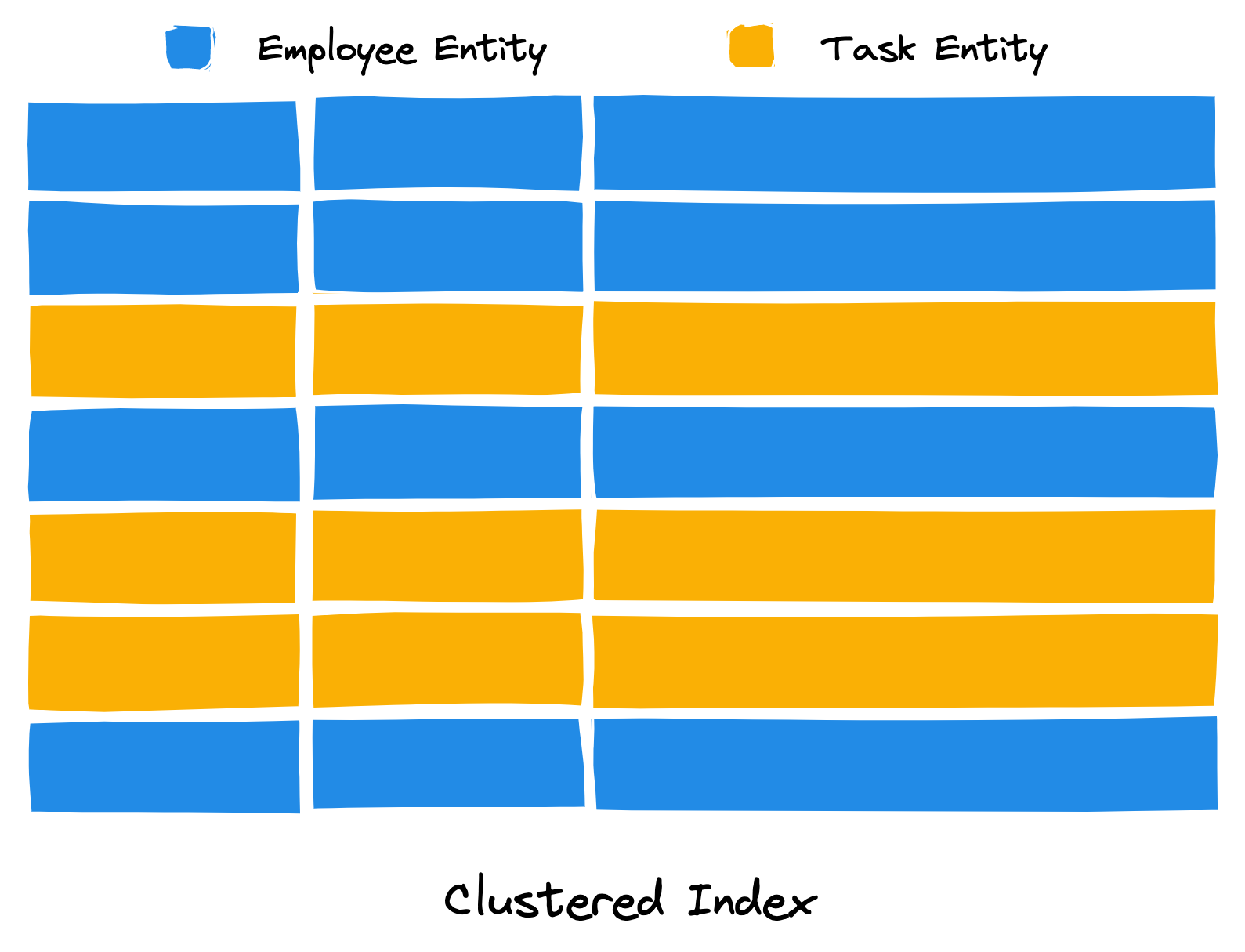
In a clustered index type, entities sharing a partition key intermix (or “cluster”) together. This is ideal for querying across entities, but not ideal for efficently targetting a single entity type.
Indexes Without Sort Keys
When using indexes without Sort Keys, that should be expressed as an index without an sk property at all. Indexes without an sk cannot have a collection, see Collections for more detail.
It is generally recommended to always use Sort Keys when using ElectroDB as they allow for more advanced query opportunities. Even if your model doesn’t need an additional property to define a unique record, having an
skwith no defined composite attributes (e.g. an empty array) still opens the door to many more query opportunities like collections.
Example
// ElectroDB interprets as index *not having* an SK.
{
indexes: {
myIndex: {
pk: {
field: "pk",
composite: ["id"]
}
}
}
}Indexes With Sort Keys
When using indexes with Sort Keys, that should be expressed as an index with an sk property. If you don’t wish to use the Sort Key in your model, but it does exist on the table, simply use an empty for the composite property. An empty array is still very useful, and opens the door to more query opportunities and access patterns like collections.
Example
// ElectroDB interprets as index *having* SK, but this model does not assign any composite attributes to it.
{
indexes: {
myIndex: {
pk: {
field: "pk",
composite: ["id"]
},
sk: {
field: "sk",
composite: []
}
}
}
}Numeric Keys
If you have an index where the Partition or Sort Keys are expected to be numeric values, you can accomplish this with the template property on the index that requires numeric keys. Define the attribute used in the composite template as type “number”, and then create a template string with only the attribute’s name.
For example, this model defines both the Partition and Sort Key as numeric:
Example
const schema = {
model: {
entity: "numeric",
service: "example",
version: "1",
},
attributes: {
number1: {
type: "number", // defined as number
},
number2: {
type: "number", // defined as number
},
},
indexes: {
record: {
pk: {
field: "pk",
template: "${number1}", // will build PK as numeric value
},
sk: {
field: "sk",
template: "${number2}", // will build SK as numeric value
},
},
},
};Index Casing
DynamoDB is a case-sensitive data store, and therefore it is common to convert the casing of keys to uppercase or lowercase prior to saving, updating, or querying data to your table. ElectroDB, by default, will lowercase all keys when preparing query parameters. For those who are using ElectroDB with an existing dataset, have preferences on upper or lowercase, or wish to not convert case at all, this can be configured on an index key field basis.
In the example below, we are configuring the casing ElectroDB will use individually for the Partition Key and Sort Key on the GSI “gsi1”. For the index’s PK, mapped to gsi1pk, we ElectroDB will convert this key to uppercase prior to its use in queries. For the index’s SK, mapped to gsi1pk, we ElectroDB will not convert the case of this key prior to its use in queries.
{
indexes: {
myIndex: {
index: "gsi1",
pk: {
field: "gsi1pk",
casing: "upper", // Acct_0120 -> ACCT_0120
composite: ["organizationId"]
},
sk: {
field: "gsi1sk",
casing: "none", // Acct_0120 -> Acct_0120
composite: ["accountId"]
}
}
}
}Casing is a very important decision when modeling your data in DynamoDB. While choosing upper/lower is largely a personal preference, once you have begun loading records in your table it can be difficult to change your casing after the fact. Unless you have good reason, allowing for mixed case keys can make querying data difficult because it will require database consumers to always have a knowledge of their data’s case.
| Casing Option | Effect |
|---|---|
default | The default for keys is lowercase, or lower |
lower | Will convert the key to lowercase prior it its use |
upper | Will convert the key to uppercase prior it its use |
none | Will not perform any casing changes when building keys |
Sparse Indexes
Sparse indexes are indexes that are only contain a subset of the items on your main table. Sparse indexes are useful when you want to reduce the number of records your query must iterate over to find the records you are looking on a secondary index. By having fewer records on a secondary index, you can improve the performance of your queries and reduce the cost of your table.
ElectroDB manages which secondary indexes are written to your DynamoDB table based on the attributes you provide to your query; this includes adding runtime constraints to ensure consistency between your index key values and its constituent composite attributes. If you wish to prevent an index from being written, you can define a condition callback on your index. The provided callback will be invoked at query-time, passed all attributes set on that mutation, and if it returns false the index will not be written to your DynamoDB table.
Example
This example shows an index called myIndex which has a provided condition callback. The attr argument contains all attributes provided to the mutation method. This includes all attributes for a put, create, or upsert and/or all attributes set on an update or patch.
{
indexes: {
myIndex: {
index: "gsi1",
condition: (attr) => attr.type === "closed"
pk: {
field: "gsi1pk",
composite: ["organizationId"]
},
sk: {
field: "gsi1sk",
composite: ["type", "accountId"]
}
}
}
}Index Scoping
When designing your indexes with Single Table Design, you may find yourself in a situation where the composite attributes of one entity’s partition key are the same as another entity. While in most cases this would be a deliberate choice, made to more easily query across entities via collections, there are times when you might desire further isolation between entities. This scenario is most commonly encountered when the partition key of both entities are defined with an empty composite array. When further isolation between entities on an index is necessary, you can use the scope property on your index to directly impact how records are partitioned.
Note: the
scopeconcept came from an RFC that was thoughtfully put forward by @Sam3d in Issue #290, which can be read for further context. Thank you, Brooke for your contribution!
The example below demonstrates how to use the scope property to isolate records on an index. In this example, the organization entity and the user entity both have a partition key of pk with an empty composite array. This means that both entities will share the same partition key, and will be stored in the same partition. This is not ideal, as it means that a query for users may also impact the throughput of a query for organizations. To isolate these entities, we can use the scope property on the index to further isolate the partition key for each entity.
const organization = new Entity({
model: {
entity: "organization",
service: "taskapp",
version: "1"
},
attributes: {
organizationId: {
type: "string"
},
},
indexes: {
myIndex: {
scope: "org", // <--- Scope is set to unique value "org"
pk: {
field: "pk",
composite: []
},
sk: {
field: "sk",
composite: ["organizationId"]
}
}
}
}, { table: "your_table_name" });
const user = new Entity({
model: {
entity: "user",
service: "taskapp",
version: "1"
},
attributes: {
userId: {
type: "string"
},
},
indexes: {
myIndex: {
scope: "user", // <--- Scope is set to unique value "user"
pk: {
field: "pk",
composite: []
},
sk: {
field: "sk",
composite: ["userId"]
}
}
}
}, { table: "your_table_name" });Without the use of scope, both entities would share the same partition key and would be stored in the same partition. With the use of scope, each entity will have a unique partition key and will be stored in a separate partition.
Without Scope
Without a scope value, notice the partition key value at ExpressionAttributeValues[‘:pk’] is the same for both queries. This occurs when composite attribute array for a partition key matches between entities. Keep in mind that, in most cases, this is desirable because it helps enable querying across entities via collections. However, in some cases, this may not be desirable which is why the scope property exists.
organization.query.myIndex({organizationId: '123'}).go();
// {
// "KeyConditionExpression": "#pk = :pk and #sk1 = :sk1",
// "TableName": "your_table_name",
// "ExpressionAttributeNames": {
// "#pk": "pk",
// "#sk1": "sk"
// },
// "ExpressionAttributeValues": {
// ":pk": "$taskapp",
// ":sk1": "$organization_1#organizationid_org123"
// }
// }user.query.myIndex({userId: '456'}).go();
// {
// "KeyConditionExpression": "#pk = :pk and #sk1 = :sk1",
// "TableName": "your_table_name",
// "ExpressionAttributeNames": {
// "#pk": "pk",
// "#sk1": "sk"
// },
// "ExpressionAttributeValues": {
// ":pk": "$taskapp",
// ":sk1": "$organization_1#organizationid_org123"
// }
// }With Scope
Notice the value at ExpressionAttributeValues[‘:pk’] now contains the scope value that was provided by the user on the index definition.
organization.query.myIndex({organizationId: '123'}).go();
// {
// "KeyConditionExpression": "#pk = :pk and #sk1 = :sk1",
// "TableName": "your_table_name",
// "ExpressionAttributeNames": {
// "#pk": "pk",
// "#sk1": "sk"
// },
// "ExpressionAttributeValues": {
// ":pk": "$taskapp_org",
// ":sk1": "$organization_1#organizationid_org123"
// }
// }user.query.myIndex({userId: '456'}).go();
// {
// "KeyConditionExpression": "#pk = :pk and #sk1 = :sk1",
// "TableName": "your_table_name",
// "ExpressionAttributeNames": {
// "#pk": "pk",
// "#sk1": "sk"
// },
// "ExpressionAttributeValues": {
// ":pk": "$taskapp_user",
// ":sk1": "$organization_1#organizationid_org123"
// }
// }Attributes as Indexes
It may be the case that an index field is also an attribute. For example, if a table was created with a Primary Index partition key of accountId, and that same field is used to store the accountId value used by the application. The following are a few examples of how to model that schema with ElectroDB:
If you have the unique opportunity to use ElectroDB with a new project, it is strongly recommended to use generically named index fields that are separate from your business attributes.
When your attribute’s name, or field property on an attribute, matches the field property on an indexes’ pk or sk ElectroDB will forego its usual index key prefixing.
Example
{
model: {
entity: "your_entity_name",
service: "your_service_name",
version: "1"
},
attributes: {
accountId: {
type: "string"
},
productNumber: {
type: "number"
}
},
indexes: {
products: {
pk: {
field: "accountId",
composite: ["accountId"]
},
sk: {
field: "productNumber",
composite: ["productNumber"]
}
}
}
}Another approach allows you to use the template property, which allows you to format exactly how your key should be built when interacting with DynamoDB. In this case composite is optional when using template, but including it helps with TypeScript typing.
Example
{
model: {
entity: "your_entity_name",
service: "your_service_name",
version: "1"
},
attributes: {
accountId: {
type: "string" // string and number types are both supported
}
},
indexes: {
"your_access_pattern_name": {
pk: {
field: "accountId",
composite: ["accountId"],
template: "${accountId}"
},
sk: {...}
}
}
}Advanced use of template
When your string attribute is also an index key, and using key templates, you can also add static prefixes and postfixes to your attribute. Under the covers, ElectroDB will leverage this template while interacting with DynamoDB but will allow you to maintain a relationship with the attribute value itself.
Example
{
model: {
entity: "your_entity_name",
service: "your_service_name",
version: "1"
},
attributes: {
accountId: {
type: "string" // only string types are both supported for this example
},
organizationId: {
type: "string"
},
name: {
type: "string"
}
},
indexes: {
"your_access_pattern_name": {
pk: {
field: "accountId",
composite: ["accountId"],
template: "prefix_${accountId}_postfix"
},
sk: {
field: "organizationId",
composite: ["organizationId"]
}
}
}
}ElectroDB will accept a get request like this:
await myEntity
.get({
accountId: "1111-2222-3333-4444",
organizationId: "AAAA-BBBB-CCCC-DDDD",
})
.go();Query DynamoDB with the following params (note the pre/postfix on accountId):
ElectroDB defaults keys to lowercase, though this can be configured using Index Casing.
{
"Key": {
"accountId": "prefix_1111-2222-3333-4444_postfix",
"organizationId": "aaaa-bbbb-cccc-dddd"
},
"TableName": "your_table_name"
}When returned from a query, however, ElectroDB will return the following and trim the key of it’s prefix and postfix:
{
"accountId": "prefix_1111-2222-3333-4444_postfix",
"organizationId": "aaaa-bbbb-cccc-dddd"
}